DeepSeek正式宣布版本R1 0528的更新:性能更接近O
- 编辑:admin -DeepSeek正式宣布版本R1 0528的更新:性能更接近O
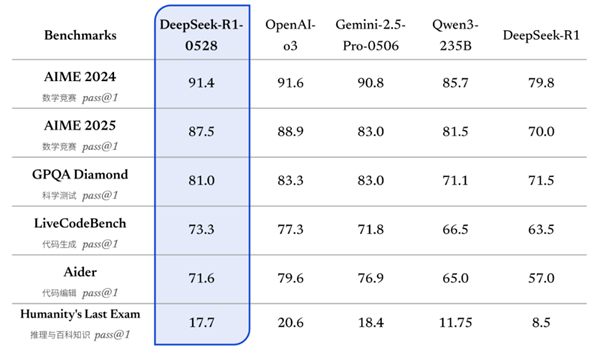 根据今晚的Kuai Technology,DePseek于5月29日正式宣布R1型号已经完成了该版本的小更新,并且当前版本为DeepSeek-R1-0528。报道说,DeepSeek-R1-0528仍然使用2024年12月推出的DeepSeek V3基本模型作为基础,但经过培训后,在此过程中投资了更多的计算机功能,从而显着提高了思想和模型推理能力的深度。更新的R1模型在所有具有多种参考评估的国家模型中都取得了顶级结果,包括数学,编程和一般逻辑,并以O3和Gemini-2.5-Pro等一般性能的其他主要国际模型来处理其他主要国际模型。与以前的R1版本相比,复杂的推理任务中模型的新版本的性能改进得到了显着改善。典型样本,在AIME 2025测试中,该模型的最新版本的精度从70%增加到87.5%以前的版本。这是因为在推理过程中改善了模型的思想深度。在AIME 2025测试集中,最古老的模型每个问题平均使用12K令牌,而新模型的每个问题平均使用了23K令牌,表明它们在解决问题的过程中具有更详细和详细的思想。同时,DePseek蒸馏了DeepSeek-R1-0528思维链,训练了Qwen3-8b,并获得了DeepSeek-R1-0528-QWEN3-8B。该8B模型仅在AIME 2024数学测试中被DeepSeek-R1-0528超过,超过QWEN3-8B(+10.0%)和Rivuring Qwen3-235b。 DeepSeek认为,DeepSeek-R1-0528的思维链对于研究学术推理模型和开发行业的小型模型非常重要。其他幻觉技能更新技巧:DeepSeek R1的新版本已针对“幻觉”的问题进行了优化。与以前的版本相比,更新的MODEL可用于改写,波兰语,总结,阅读理解等。幻觉率在舞台上降低了约45-50%。创意写作:基于先前版本的R1,更新的R1模型进一步优化了有争议的测试,小说,散文和其他样式,这是最长的工作生产,具有更完整的长度,结构和内容,并且可以呈现与人类偏好接近的写作样式。 [本文的结尾]如果您需要重印,请务必向我们展示其来源:Kuai技术编辑:Shiqi
根据今晚的Kuai Technology,DePseek于5月29日正式宣布R1型号已经完成了该版本的小更新,并且当前版本为DeepSeek-R1-0528。报道说,DeepSeek-R1-0528仍然使用2024年12月推出的DeepSeek V3基本模型作为基础,但经过培训后,在此过程中投资了更多的计算机功能,从而显着提高了思想和模型推理能力的深度。更新的R1模型在所有具有多种参考评估的国家模型中都取得了顶级结果,包括数学,编程和一般逻辑,并以O3和Gemini-2.5-Pro等一般性能的其他主要国际模型来处理其他主要国际模型。与以前的R1版本相比,复杂的推理任务中模型的新版本的性能改进得到了显着改善。典型样本,在AIME 2025测试中,该模型的最新版本的精度从70%增加到87.5%以前的版本。这是因为在推理过程中改善了模型的思想深度。在AIME 2025测试集中,最古老的模型每个问题平均使用12K令牌,而新模型的每个问题平均使用了23K令牌,表明它们在解决问题的过程中具有更详细和详细的思想。同时,DePseek蒸馏了DeepSeek-R1-0528思维链,训练了Qwen3-8b,并获得了DeepSeek-R1-0528-QWEN3-8B。该8B模型仅在AIME 2024数学测试中被DeepSeek-R1-0528超过,超过QWEN3-8B(+10.0%)和Rivuring Qwen3-235b。 DeepSeek认为,DeepSeek-R1-0528的思维链对于研究学术推理模型和开发行业的小型模型非常重要。其他幻觉技能更新技巧:DeepSeek R1的新版本已针对“幻觉”的问题进行了优化。与以前的版本相比,更新的MODEL可用于改写,波兰语,总结,阅读理解等。幻觉率在舞台上降低了约45-50%。创意写作:基于先前版本的R1,更新的R1模型进一步优化了有争议的测试,小说,散文和其他样式,这是最长的工作生产,具有更完整的长度,结构和内容,并且可以呈现与人类偏好接近的写作样式。 [本文的结尾]如果您需要重印,请务必向我们展示其来源:Kuai技术编辑:Shiqi



